
Last week the 2015 ISI Impact Factors were announced. Hopefully this was not a date circled on your calendar. But if you were on a editorial board you could not escape a quick announcement of your journal’s new impact factor, whether it gained or lost in rank relative to other journals, and cheers and (email) back-slaps all around or solemn faces and vows to do better. And in my experience authors will now switch allegiance in which journals they submit to so as to follow those ranked highest in impact factor. Is this justified?
First the obligatory disclaimer about impact factors. First and foremost they are metrics of a journal and not metrics of a paper or a scientist. We all know they get used to judge individual scientists or papers (e.g. “so and so published in a journal with an impact factor over 30 so they’re sure to get a job”). But we also all know this is wrong. Here is why its wrong. The number of citations received by different papers within a journal is very skewed and lognormal or power-law like with a lot of variance. Thus it is quite possible (actually probable) that a paper published in a journal with an impact factor of 30 will have an individual impact much less than 30. If you want to evaluate a scientist look at their citation rates or plain old read their papers. Impact factors don’t tell you much.
That said, impact factors are one valid measure of journal quality. It is a one dimensional representation of a high dimensional concept (journal quality), with the many limits innate in that fact. In particular impact is focused on raw number of citations – not citations in influential journals nor citations in diverse journals (eigenvector statistics do these better). And it is a really time specific window. The 2015 impact factors are based on the number of times papers published in 2013 or 2014 are cited in 2015. Thus it is really tuned to measuring citations 1-2 years after publication. Not citations 6 months after citation, which is a good signal of really hot papers. Nor is it citation over longer windows capturing papers that take time to appreciate or in slower moving fields (you can find 5 or 10 year impact factors but everybody focuses on the two year ones).
But here is my biggest complaint about impact factors. And its not really a complaint about impact factors, but how we use them. It seems to me scientists behave very unscientifically around impact factors. Any number we report in our science has a limited number of decimal places with error bars to represent our ignorance. Its downright hard to get a number past reviewers without reporting error bars. But when we look at impact factors we report them to two decimal places and no error bars.
This is wholly unjustified. The error bars are very large. The one paper I know of that seriously looks at error bars is by Sterns (Uncertainty measures for economics journal impact factors) is quite revealing. The 95% confidence intervals are large. So a journal with an impact factor of 9.281 has a 95% chance of actually being in (11.986,6.576) or 3.443 gives (2.467,4.419) or 5.676 gives (5.056,6.403). This was done using an asymptotic method, not bootstrapping. Given the finite samples and skewness I would expect the real confidence intervals to be even larger then this method suggests. And these are 5 year impact factors – the 2 year impacts should be still noisier (i.e. larger confidence intervals). And note, this is not including year-to-year variability. Probably a perfect design would resample citation rates across not just the two year (or 5 year) window of interest. I haven’t done this and am not aware of anybody else who has, but suffice it to say that the above reported intervals are quite conservative, especially taking into account year-to-year variability where the set of articles is allowed to vary.
Why are the confidence intervals so large? As a colleague, Janet Franklin, is fond of saying, impact factors are means not medians. But we all know that when the data is highly skewed, means poorly represent the data. This is why income distributions are reported as medians. Superstar performers and athletes making over $100,000,000/year skew the means too much to be representative. The same with house prices. Or to be even more direct, recall the formula for the 2015 impact factor is:
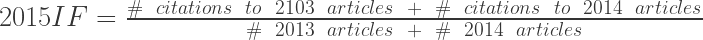
Now lets look at a typical strong ecology journal with an impact factor around 3-5. It probably has about 80-150 articles published each year. Lets say 100. So the denominator is 200. The numerator is the sum of all the 2015 citations to 2013 and 2014 articles. This is a highly skewed lognormal distribution. This means most of the articles have been cited zero or one times (HT Jeff Ollerton). And there are a handful of articles that have been cited 50 times. And if you’re super lucky there will be one or two cited over 100 times. Maybe even 500 times. Now think about that for a second. If you get one of the papers that goes “viral” and is cited 500 times that goes into the numerator along with all of those papers cited no times or once. And the denominator is 200. That means that one paper is driving 2.5 points (not percent, points!) of your impact factor. You might think this is a made up example, but its highly realistic. Amongst the high end ecology journal, those that saw their impact factors go up in 2015 are those that had a paper with 300-400 cites, or a couple with 100+ cites in 2013 or 2014. Journals that went down often had such a paper (or set of a few papers) published in 2012 that got removed from the 2-year window this year. I’m not going to pick on specific journals and give specific examples, but I could – I have specific papers and journals in mind when I say this.
What kind of papers get those super-highly cited statistics? Usually they are reviews, often of methods, and often of common statistical issues. And often they are opinion pieces by well-known ecologists. Those are important papers that deserve to be well-cited. But given that they are one or two papers a year, they probably have undue influence on a journal’s impact factor. Science and Nature are really no different – most of their impact factor is driven by the handful of papers that contain whole species genomes or talk about a method generic cross fields like network theory and are cited 1000+ times
So I started by saying impact factors are limited but useful in evaluating journals. Now I seem to be saying they are very noisy. What gives? They’re both true. We’re ecologists we should be able to deal with noisy data. But it seems we don’t with impact factors. Every year you hear about a journal that fell 3 places or rose 3 places in the rankings when the differences is often just 0.5 of an impact factor and that almost certainly comes down to a single paper or two – i.e. is well within the error bars, especially when year-to-year variability is taken into account. Yet authors duly switch which journals to prioritize each year based on this. To be honest, this is just silly.
Impact factors give very broadly a crude, coarse-grained ranking, but nothing more. To my mind, I take impact factors, round to the nearest integer, and assume error bars are about + or – 1 impact point. If two journals aren’t separated after doing that you’re probably focusing on noise rather than signal. And you might realistically want to use +/- 2 impact points to have much confidence. And it probably takes 4 or 5 years to count as a trend up or down. Used that way, they have some value. Reporting two decimal places and obsessing whether a journal slipped up or down one place in the rankings or deciding which journal to submit to based on a single years impact factors* is a misuse.
* You could make a pretty good argument that deciding which journal to submit to based on impact factor at all is a misuse, but that is a topic for another day and another post.

I’m now curious which one paper dropped out of EcoLetts’ IF and caused it to drop from 18 to 12 in one year (if memory serves)…
“Impacts of climate change on the future of biodiversity?”
published in 2012 with 424 citations today, the highest cited paper from 2013 has 121. 2014 max is 62, 2015 is 25, so the effect of age magnifies the difference between 2012 and 2013’s highest cited papers obviously…
Yep – its an open secret that if you want to manipulate impact factor you put your best papers in January so they have the most time to accumulate citations. And a really good paper in the first year (2013 for 2015 impact factors) is better than the second year. One reason why we should maybe think about paying more attention to 5 year impact factors. These flukes (or manipulations) of timing get evened out.
This post certainily have a point. Now, thinking on an institution, I guess it is the same bias when grading Universities and departments based on indicators such as the Impact factors. Even more, thinking on a scientist career, my sense is that single scientist impact factor have the same behavoir; luckyli, only one or two of their works go ‘viral’. I definitivelly see this as a great issue, even more when there are entire countries where jobs tenures depend on measures like this.
“And in my experience authors will now switch allegiance in which journals they submit to so as to follow those ranked highest in impact factor. ”
Really? My own internal “ranking” of journals is little changed since I finished grad school in 2000. Does that make me unusual?
Yes! We found that a 10% increase in Mol Ecol’s IF typically led to a ~7% increase in submissions. A decrease in IF led to a drop in subs.
That’s kind of depressing to hear. Like when Cornell started publishing the average grades in each course and enrollments shifted towards courses and majors with higher grades. (I think it was Cornell; we linked to this in an old linkfest but I can’t find it just now…)
Now that I think of it, I recall that Plos One’s submissions seem to track its IF with a bit of a lag; Phil Davis has a couple of posts on this at the Scholarly Kitchen.
“internal “ranking” of journals is little changed since I finished grad school in 2000. Does that make me unusual?”
I think so, yes. Many journals I regularly consider and really like were barely on the radar in 2000: Ecography, Ecology Letters, GEB, Global Change Biology. And many of their papers that I like the most would have probably been in Ecology or Am. Nat. or Oikos circa 1995.
@Mark:
You’ve hit on the big way I’ve allowed my internal “ranking” to get out of step with that of the field as a whole: not “rating” Ecography and GEB higher and not paying sufficient attention to papers in those journals. I probably need to change that and update my internal mental model of the publishing landscape.
I should probably clarify that I rated EcoLetts very highly by 2000 (I was an “early adopter”).
I’m aware that GCB is high on many folks’ radars, but tend not to follow it closely myself just because I don’t work on anything even vaguely global change-related.
I don’t have data like Tim does and my experience with GEB is too short, but from conversations with editors, and getting a pretty good read of the papers sent to GEB after being rejected somewhere else (almost all from clearly higher ranking journals). I have little doubt, Jeremy, that you are unusual in not being more slavish to impact factors. And its worth noting that Molecular Ecology is one of the top few journals and so doesn’t swing massively in rank with every 0.5 shift in IF like the middle of the pack ecology journals with an IF of 2 or 3 or even 4 do. I imagine those journals see much bigger swings in submissions with IF.
There’s a really interesting discussion of how the IF is calculated here: https://scholarlykitchen.sspnet.org/2016/04/12/on-moose-and-medians-or-why-we-are-stuck-with-the-impact-factor/
It turns out that it’s a mean and not a median because they don’t use the article level data – they just have the total number of articles and the total number of citations.
“It turns out that it’s a mean and not a median because they don’t use the article level data – they just have the total number of articles and the total number of citations.”
Really?! Huh, I’d never have guessed that. You learn something new every day!
Thanks Tim – I totally forgot about that link, but its a good one – especially the comments. As the comments point out, I suspect the real reason we don’t use median IF is that there would be a huge number of journals with an IF of 0 and another big pile with an IF of 1. I would guess that a majority of all journals would go in those two bins – and they would all be tied – which breaks our human desire for a well-reserved pecking order. And to the uninitiated, those journals would come off badly.
Pingback: Science News: Oso Has a Had Long History of Landslides, What Happens When You Lick a Banana Slug - Seattle Events Live
Pingback: The state of academic publishing in 3 graphs, 6 trends, and 4 thoughts | Dynamic Ecology